
大家好,欢迎来到IT知识分享网。
原创,未经授权请勿转载!
开发基于python3.7(非Python2);
IDE是pycharm2019社区版(足够用了);
重点告诫!本文章仅供Python交流学习!
严重警告!请勿用于非法用途!
友情提醒!爬虫爬得好,牢饭吃得早!
侵删!侵删!侵删!重要的事情要说三遍。
产品需求:
1、 代码可以将笔趣阁完本小说分栏(共800多部)每本小说的简介和章节链接爬取下来,存入本地的csv文件或者mysql数据库;
2、 如果在csv文件翻看简介的时候,遇到感兴趣的小说时,可以实现代码快捷下载,将对应的小说一键下载到本地;
(ps:1的话,这个分栏可以爬,那么所有的分栏都可以爬了,只是这样对人家网站不太好,咱们也不需要那么多,看不完,所以只下载小说比较少的完本分栏;2的话,还是同样的道理,咱们只用下载比较想看的就可以了,不要贪多,对人家网站不太友好,损人不利己,要不得。)
技术难题:
额,没有…如果非要算的话,网页肯定对爬虫速度访问有所限制,这时候要用到:
1、 伪装请求头;
2、 爬取等待(就是爬一个停一下),但一个个爬,一个个等,太耗时间,决定使用多线程同时爬,各等各的,就可以把效率提上去了;
(ps:有小伙伴会说,python有GIL,所以不存在多线程,或者多线程性能提升不明显。但是这里主要是为了解决爬虫等待问题和IO密集型,不是针对科学计算,所以多线程的提升还是非常明显的,试过之后就明白啦。)
基本思路(代码结构吧):
爬虫框架肯定是首选Scrapy,但楼主用Scrapy不太多,前段时间因为不太明白Scrapy如何使用代理,所以搁置了,但是Scrapy的设计框架给了楼主很大启发,但这里只是个非常简单的爬虫,楼主就随性得写了,以后可以再回来优化框架和性能。
下载器使用requests包;
网页内容解析使用BeautifulSoup包;
准备工作:
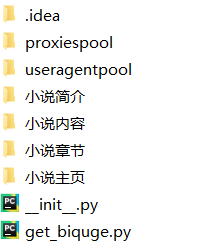
1、先把基本的爬虫结构图画出来(使用表格吧):
| 一级文件夹 | 二级文件夹 | 说明 |
|---|---|---|
| get_biquge | proxiespool | 存放IP代理池和调用代码proxiespool.py |
| useragentpool | 存放UserAgent代理池和调用代码useragentpool.py | |
| 小说主页 | 存放爬取到的单个小说的主页地址到本地 | |
| 小说简介 | 存放爬取到的单个小说的简介到本地 | |
| 小说章节 | 存放爬取到的单个小说的所有章节和章节地址到本地 | |
| 小说内容 | 存放爬取到的单个小说的章节内容到本地 |
2、准备伪装的请求头代理池useragentpool
这里是使用楼主自己编写的useragentpool包,从本地txt文件中读取。
使用它的实例化方法ua_next(),可以实现UserAgent的循环使用;
使用它的实例化方法ua_random(),可以实现UserAgent的随机获取;
代码如下:
# coding:utf-8
# python 3.7
import random
import itertools as its
class ua(object):
# 楼主提前准备好的30多个UserAgent存在了同目录下的useragentpool.txt里,每行一个。
def __init__(self,dir='useragentpool/useragentpool.txt'):
self.result_list = []
with open(dir,'r',encoding='utf-8') as f:
for i in f.readlines():
i = i.strip('\n')
self.result_list.append(i)
*# 这里是将获取到的UA的列表转成迭代器,方便使用next()方法,要用到itertools包下的cycle方法,*生成一个无限循环的迭代器;
self.its = its.cycle(self.result_list)
def ua_random(self):
return random.choice(self.result_list)
def ua_next(self):
return next(self.its)
if __name__=='__main__':
pass
useragentpool.txt的内容格式大概就是这样的,点开查看
3、 准备代理池,用来提高爬取速度
这里是使用楼主自己编写的proxiespool包,从本地txt文件中读取代理IP和port。
ps:这里的txt文件中的内容,是UP主从代理网站上,付费获取的JSON格式
使用它的实例化方法ua_next(),可以实现UserAgent的循环使用;
使用它的实例化方法ua_random(),可以实现UserAgent的随机获取;
代码如下:
# coding:utf-8
# python 3.7
import json
import random
import itertools as its
class px(object):
def __init__(self):
with open(r"proxiespool\org_ppool.txt","r",encoding='utf-8') as f:
self.t = f.read()
t = json.loads(self.t)
ip = t['domain']
port = t['port']
self.p_list = ['http://{0}:{1}'.format(ip,j) for j in port]
self.p_its = its.cycle(self.p_list)
self.out = {
}
def px_random(self):
temp = random.choice(self.p_list)
self.out['https'] = temp
self.out['http'] = temp
# 生成一个供requests使用的proxies字典
return self.out
def px_next(self):
temp = next(self.p_its)
self.out['https'] = temp
self.out['http'] = temp
return self.out
if __name__ == "__main__":
pass
ps: useragentpool.txt,和useragentpool.py文件,都放在useragentpool文件夹中;
org_ppool.txt,proxiespool.py文件,都放在proxiespool文件夹中;每个文件夹都要创建一个__init__.py文件(这是为啥,就不用我说再细说了吧。)
正式工作:
所有的爬取代码都放在了 get_biquge文件夹的get_biquge.py文件里。
具体三步:
1、 先获取笔趣阁完本小说分栏下的所有小说的首页地址,存入本地的 小说主页 文件夹中,按照固定格式命名的csv文件;
2、 在通过1获取的地址,爬取每个小说的简介,存入 小说简介 文件夹中,按照固定格式命名的csv文件;同时,将每个小说的所有章节的地址存入单独的csv文件中,放在 小说章节 文件夹里;
小说简介文件类似于这种格式,点开查看
按照小说名和作者命名的csv文件,点击查看
这里是单个小说csv文件中每一章节的url地址,点击查看
3、在2的基础上,选择想读的小说,进行批量下载,每一章一存,在 小说内容 文件夹中创建对应小说名的文件夹,将每一章存成txt格式存入其中;
代码实现:
# coding:utf-8
# python 3.7
import pandas as pd
import requests
from useragentpool import useragentpool
from proxiespool import proxiespool
import time
from bs4 import BeautifulSoup
import os
from concurrent.futures import ThreadPoolExecutor
import itertools as its
import re
class get_novel(object):
#这里是先将准备工作做好,将起始的爬取页、两个代理池以及系统日期和时间都提前生成好
def __init__(self,start=r'http://www.biquge.tv/wanben/1_'):
# 这里先导入启示爬虫页面
self.start_url = start
# 这里是导入生成随机或者循环useragent池
self.UA = useragentpool.ua()
# 这里是导入生成循环中断时间代理池
self.stop = its.cycle([1,1.5,2])
# 这里是导入生成随机或者循环proxies代理池
self.PX = proxiespool.px()
# 这里是获取当前系统时间
self.time = time.strftime("%m-%d_%H-%M",time.localtime(time.time()))
# 第一步:先从start_url上获取小说所有的主页地址,存入本地 小说主页 文件夹,因为页面少,所以暂不使用多线程、设置等待;
def get_novellist(self,n=29):
# n是小说列表的页数
headers = {
'User-Agent': self.UA.ua_next()}
result_list = []
for i in range(1,n+1):
# 这里需要构建列表地址的url
n_list_web = requests.get(r'{0}{1}'.format(self.start_url,i),headers=headers,timeout=5)
time.sleep(next(self.stop))
n_list_web.encoding='gbk'
soup = BeautifulSoup(n_list_web.text,'lxml')
title_list = soup.find('div', class_="l").find_all('li')
for j in title_list:
single_novel = []
single_novel.append(j.find('span', class_='s2').text.strip("《|》 \n"))
single_novel.append(j.find('span', class_='s5').text.strip("《|》 \n"))
single_novel.append(j.find('a')['href'].strip())
result_list.append(single_novel)
print(single_novel)
result_df = pd.DataFrame(result_list, columns=['小说名', '作者名', '链接'])
result_df.index.name = '序号'
print(result_df)
# 这里的encoding可以使用'utf-8',此处用'ANSI'是为了能够用Excel方便打开看。
result_df.to_csv(r"小说主页/完本小说.csv", encoding='ANSI')
# 第二步:从本地的csv表中提供的小说地址开始,生成获取每个小说的标题、作者、简介、章节的名称列表、单章地址,并且创建对应文件夹;
# 这次因为数量太多,要用到多线程和代理IP啦。
def get_charpterlist(self,st=0,end=None,workers_n=8):
novel_list = pd.read_csv('小说主页/完本小说.csv',encoding='ANSI',index_col='序号',header=0)
if end==None:
end = novel_list.shape[0]
novel_list["简介"] = "空"
# 生成一个函数,对单个小说列表和简介进行提取,s是single的意思
def get_s_charpter_list(i):
print("{}start".format(i))
name = novel_list.iloc[i, 0]
writer = novel_list.iloc[i, 1]
url = novel_list.iloc[i, 2]
c_web = requests.get(url, headers={
'User-Agent': self.UA.ua_next()},proxies = self.PX.px_next(),timeout=5)
time.sleep(next(self.stop))
c_web.encoding = 'gbk'
soup = BeautifulSoup(c_web.text, 'lxml')
intro = soup.find('div', id='intro').p.text.strip()
novel_list.iloc[i, 3] = intro.strip().replace(" ","")
# print(i, intro)
charpter_total_list = soup.find('div', id='list').find_all('dd')
out_chapter_list = []
for j in charpter_total_list:
# 这里的c_list是单个小说的章节名,和章节连接并且直接生成CSV文件。
c_list = [j.text.strip(), 'http://www.biquge.tv{}'.format(j.a['href'])]
out_chapter_list.append(c_list)
out_chapter_df = pd.DataFrame(out_chapter_list, columns=['章节名', '章节地址'])
# 这里是删掉重复的章节名
out_chapter_df.drop_duplicates(keep='last', inplace=True)
out_chapter_df.reset_index(drop=True, inplace=True)
out_chapter_df.index.name = '序号'
out_chapter_df.to_csv('小说章节/{0:0>4d}_{1}_{2}.csv'.format(i, name, writer), encoding='ANSI')
print("{}end".format(i))
try:
with ThreadPoolExecutor(max_workers=workers_n) as executor:
executor.map(get_s_charpter_list,range(st,end))
novel_list.to_csv("小说简介//{}_小说简介.csv".format(self.time), encoding='utf-8')
except:
novel_list.to_csv("小说简介//{}_小说简介.csv".format(self.time), encoding='utf-8')
dir_list = os.listdir("小说章节")
dir_df = pd.DataFrame(dir_list)
dir_df.to_csv("小说简介/爬取到的小说列表.csv",index=True,encoding='ANSI')
#ps:这里因为UP主的代理IP时间有限制,每次只能十分钟,所以只好使用8线程,如果同样的IO的话,不用设置等待时间的话,测试结果是4线程最快,暂时还不清楚为什么。
# 第三步:选择对应的小说将每一章节都下载到本地对应的文件夹;
# 第三步A 编写从单独csv文件中提取csv并下载的对应的链接和章节名,放到对应的文件夹中
def get_single_novel(self,csv,workers_n=8):
df = pd.read_csv(csv,encoding='ANSI')
_,novel_name,_ = re.split("/|\.",csv)
single_dir_name = "小说内容/{}".format(novel_name)
try:
os.makedirs(single_dir_name)
except:
pass
def get_charpter(i):
name = df.iloc[i,1]
url = df.iloc[i,2]
# 这里是调节是否使用多线程,默认使用8个线程
# req = requests.get(url,headers={'User-Agent': self.UA.ua_next()},timeout=5)
req = requests.get(url, headers={
'User-Agent': self.UA.ua_next()}, proxies=self.PX.px_next(), timeout=5)
time.sleep(next(self.stop))
print("{}已开始。".format(name))
req.encoding = 'gbk'
soup = BeautifulSoup(req.text, 'lxml')
body = soup.find('div', id='content').text.strip()
# print(body)
with open("{0}/{2:0>4d}{1}.txt".format(single_dir_name,name,i),"w",encoding='utf-8') as f:
f.write(body)
print("{}已完成。".format(name))
with ThreadPoolExecutor(max_workers=workers_n) as executor:
executor.map(get_charpter,range(df.shape[0]))
# executor.map(get_charpter, range(10))
# 第三步B 这个函数汇总下载小说,可以通过设置st,end参数,下载对应的小说
# 默认是只下载前50个,目测一本是平均1000章1000个网页,5分钟左右可以下载完一本。
def get_total_novel(self,st=0,end=50,workers_n=8):
n_list = os.listdir("小说章节")
n_list = ["小说章节/{0}".format(i) for i in n_list]
for i in n_list[st:end]:
self.get_single_novel(i,workers_n=workers_n)
print("小说{}已完成。".format(i))
if __name__=='__main__':
# 实例化
GN = get_novel()
# 下载单个小说的主页url
GN.get_novellist()
# 下载小说的章节列表和简介到文件夹
GN.get_charpterlist()
# 打开 小说简介 文件夹,从小说简介csv文件中,找到想看的小说,比如《三国之熙皇》
# 再打开,爬取到的小说列表.csv,查看到它的索引号是282,将282参数输入到get_total_novel参数,可以下载单本小说;
# ps:原谅UP主对三国小说情有独钟。
GN.get_total_novel(st=282,end=283)
# 这里解释一下文件中的索引号和原来不一致的问题,主要是多线程爬取的时候,可能会丢网页,这让人很无奈,所以只能再重新看一眼新索引,不过也能解决,但UP有点懒了,就等下次有空再搞定吧。
# 下载多部小说的话,如果是连续的话,直接将st和end参数改成对应索引就行了;如果不连续,就只能再多输几次索引号啦,也能改进,不过还是UP有点懒,回头再来优化吧,哈哈哈哈!
待改进的地方
总体上来说,能满足爬取需求,但是还是有几处可以在以后改进的地方:
1、 这是用一台电脑爬,速度还是太慢,以后要学习分布式网络的技能,从多个服务器同时爬取,速度会快很多;
2、 因为代理时间受限,可能会出现爬取超时,导致获得空白信息,这个,主要是UP主没钱,买不起静态代理IP,解决方法是,多赚些钱!
ps: 欢迎大家留言,可以问技术细节,提提改进意见,或者有什么想实现的爬虫和python数分需求,也可以说,UP反正最近比较闲,有时间搞搞事。
注册了个微信公众号,就叫 梁峻搞Python 虽然还没想好发些什么……就只说句,欢迎关注吧。
咱们下期再见!
梁峻。
免责声明:本站所有文章内容,图片,视频等均是来源于用户投稿和互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权各归其原作者或其出版社所有。如发现本站有涉嫌抄袭侵权/违法违规的内容,侵犯到您的权益,请在线联系站长,一经查实,本站将立刻删除。 本文来自网络,若有侵权,请联系删除,如若转载,请注明出处:https://yundeesoft.com/25237.html

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}